Sponsor: Using RabbitMQ or Azure Service Bus in your .NET systems? Well, you could just use their SDKs and roll your own serialization, routing, outbox, retries, and telemetry. I mean, seriously, how hard could it be?

When notifying other parts of a system of state changes I recommend creating integration events (also referred to as notifications). They are really low coupling because the producer doesn’t care who the consumers are. They simply publish integration events to a message broker and go on their merry way.
Loosely Coupled Monolith
This blog post is apart of a series of posts I’ve created around Loosely Coupled Monoliths. Although not specific to a monolith as this blog post applies to many architectures including microservices.
YouTube
Check out my YouTube channel where I post all kinds of content that accompanies my posts.
Fat Events
Events generally start out thin but over time get polluted with more and more data that consumers need. Take for example the following OrderPlaced event that is published from our Sales bounded-context.
It only contains the OrderId, which may not seem entirely useful for other parts of the system. Let’s say that another bounded context called Shipping needs the ShippingAddress. We then add that to our OrderPlaced event.
As time goes on, if we’re not careful, we may add more and more data to this event. The next thing you know you have a fat event.
Thin Events
The alternative I see the most often are thin events that contain, for the most part, just IDs. This then requires the consumer to request back to the publisher to get the relevant data.
The flow of this is demonstrated below.
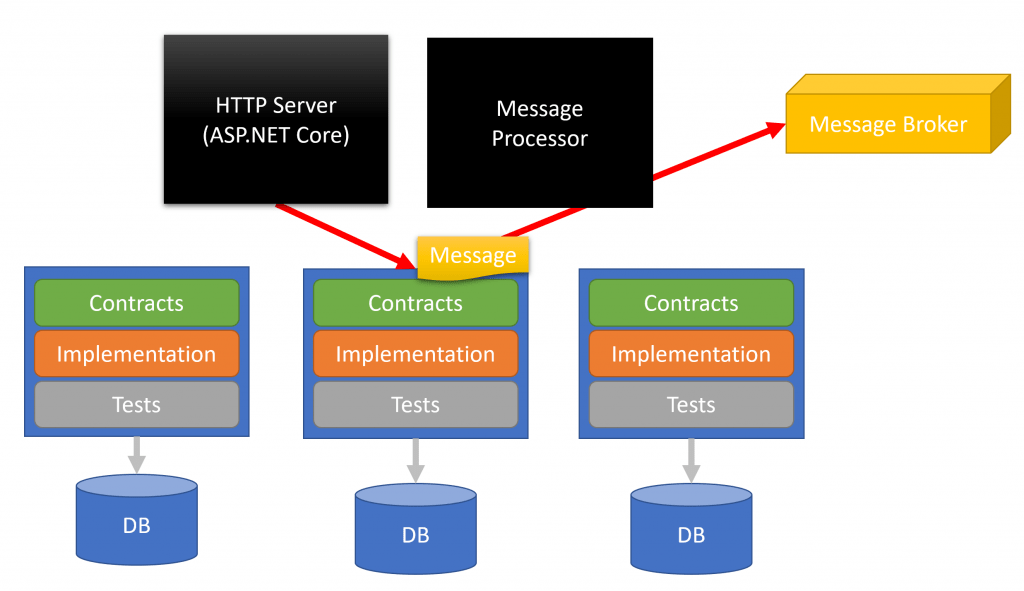
An HTTP request is made to our HTTP server which passes our request to a particular context/service. It then publishes a message to a message broker.
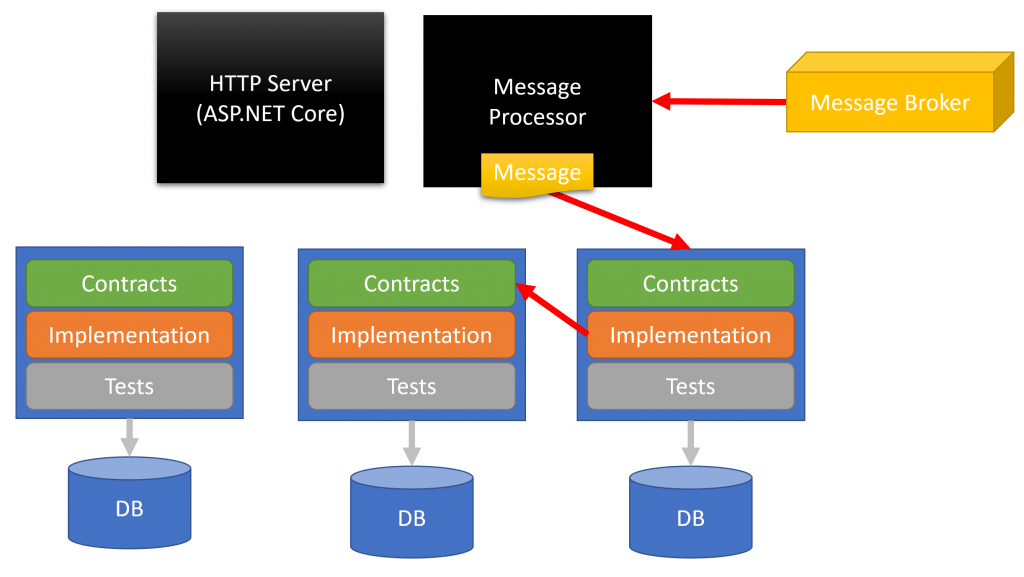
The message is then distributed to another context/service which now has to make a synchronous call (over HTTP, gRPC, whatever) to the context/service that published the event in the first place.
This is undermining the loose coupling we are achieving through asynchronous messaging. If we must make a synchronous call (via HTTP, gRPC, whatever) back to the producer of the event, then we require the producer to be available for us to get the relevant data.
If the producer isn’t available, do we have a local cache? Can we even use the local cache? Do we need the most up to date information to proceed with how we want to react to the event?
Boundaries
As mentioned earlier in my example, there is a Shipping bounded context that needed the ShippingAddress in the OrderPlaced event. And since we don’t want to synchronously call the Sales service to get that data, what do we do?
My example of the OrderPlaced event is very is deliberate. In this particular case, the boundaries are wrong.
The Shipping bounded context should own the ShippingAddress and how it receives it. Not the Sales or through the OrderPlaced.
Client Generated IDs
The key is generating IDs where the workflow occurs. In this case, it may be the client. If we generate the OrderId at the client, then we can make the relevant requests to each bounded context in the workflow to add our shipping information and place the order.
The flow of this is demonstrated below:
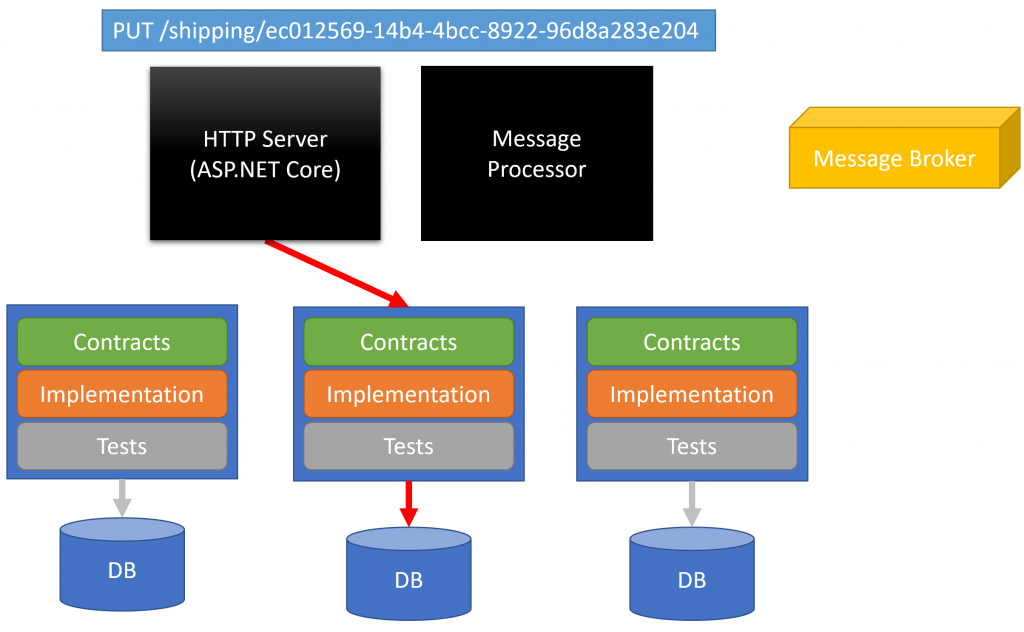
The client makes a PUT request with the address as the body/payload to our shipping bounded context with the URI of /shipping/ec012569-14b4-4bcc-8922-96d8a283e204. This GUID in the URI is our OrderId.
Although we don’t even have an order yet, we’re associating the address we want to persist with this particular OrderId.
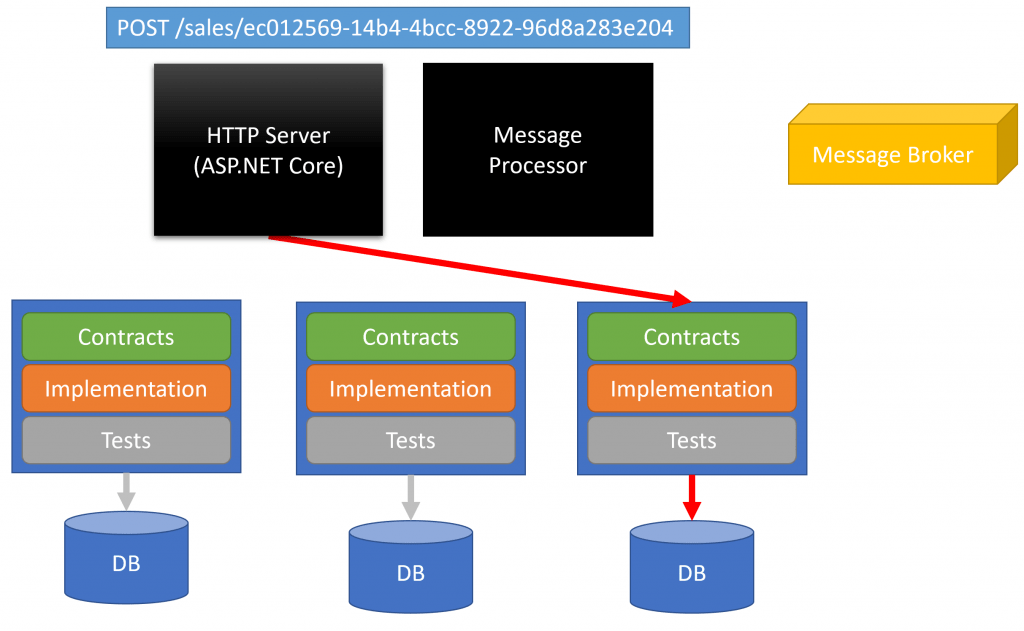
Next, the client makes a request to the Sales bounded context to place the order. Notice it’s using the same OrderId in the URI.
Now when our OrderPlaced event is published and picked up by the Shipping bounded context, it already has the shipping information. It does not need it in the OrderPlaced event, nor does it need to make a call to the Sales bounded context to get it.
Event-Carried State Transfer
Context is king. Although I prefer thin events with well defined boundaries, some situations you may prefer to use fat integration events. None are bigger than Event-Carried State Transfer events. These events basically contain the entire state (at time of publish).
This is useful for having local caches of other bounded-context/service data. This reduces the need to make asynchronous calls to the other services but at the same time involves more complexity as you are maintaining your own copy of the state locally.
Questions or Feedback
If you have any questions or comments, let me know in the comments of the YouTube video, in the comments on this post or on Twitter.