Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Microservices are a distributed system so CAP Theorem must apply right? Well, that depends on how you define microservices and a distributed system! Microservices are defined as “loosely coupled services oriented architecture with bounded context”. SOA implies Event Driven Architecture. If your microservices are loosely coupled, they aren’t making direct RPC calls to each other. If this is the case, then there are no partitions that can occur between services. If services are a bounded context and own their own data, then there is no consistency between services.
CAP does not apply to Microservices if they are loosely coupled and are a bounded context.
Here’s a breakdown and to further explain why the question “Does CAP Theorem apply to Microservices?” doesn’t even make sense and has no relation to Microservices.
YouTube
Check out my YouTube channel where I post all kinds of content that accompanies my posts including this video showing everything that is in this post.
CAP Theorem
In theoretical computer science, the CAP theorem, also named Brewer’s theorem after computer scientist Eric Brewer, states that it is impossible for a distributed data store to simultaneously provide more than two out of the following three guarantees:
Consistency: Every read receives the most recent write or an error
Availability: Every request receives a (non-error) response, without the guarantee that it contains the most recent write
Partition tolerance: The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes
When a network partition failure happens should we decide toCancel the operation and thus decrease the availability but ensure consistency
https://en.wikipedia.org/wiki/CAP_theorem
Proceed with the operation and thus provide availability but risk inconsistency
The CAP theorem implies that in the presence of a network partition, one has to choose between consistency and availability.
An example I often see which explains CAP pretty well is the use case of an ATM. Let’s say there are 2 ATMs that communicate over the network. Anytime you go to deposit money into an ATM, it confirms the other ATM is online and available.
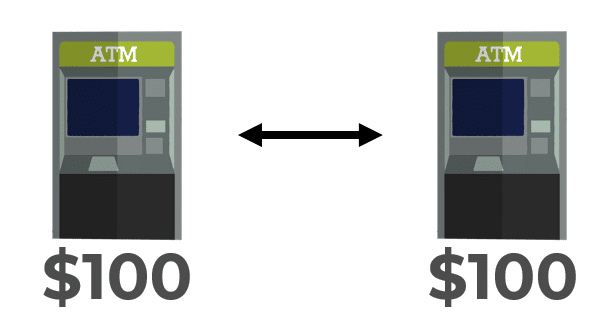
If both ATMs are online and available and you make a deposit of $100, both ATMs will have recorded that deposit. If you go to the other ATM and check your balance it will be $100. Both ATMs are consistent.
When a network partition occurs, we must choose consistency or availability.
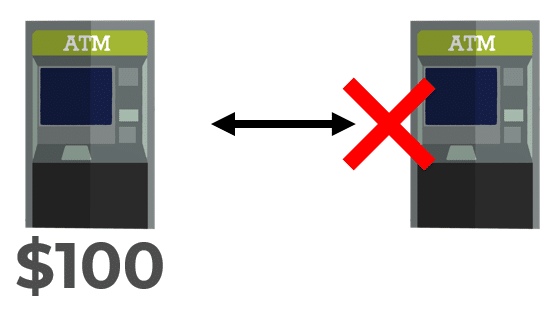
If we choose consistency, then if we cannot communicate between ATMs, then we cannot allow a deposit at one ATM because it will not be consistent with the other ATM.
If we choose availability, then we will allow the deposit to occur, however, if we go to the other ATM, it won’t be aware of our $100 deposit. Our system would have to reconcile the differences between ATMs when they are able to communicate.
So back to the question: Does CAP Theorem apply to Microservices? Well, what’s the definition of Microservices?
Microservices
Adrian Cockcroft defined Microservices as:
loosely coupled service oriented architecture with bounded contexts
https://www.slideshare.net/adriancockcroft/dockercon-state-of-the-art-in-microservices
This is very different than a distributed system where each node provides the same capabilities and data. Microservices are about the decomposition of a larger system. Each microservice has its own behavior and its own data. Comparing the two systems are like comparing apples and oranges.
But there are two key points that I’d like to talk about in Adrian’s definition that really drive this home. Loosely coupled and bounded context.
Bounded Context
The concept of a bounded context from Domain Driven Design is about creating a boundary. Adrian says:
If you have to know too much about surrounding services you don’t have a bounded context.
This is because concepts should be owned by a particular bounded context within a subdomain. One service shouldn’t have to know explicitly about the details of other services. Services are about defining business capabilities and the data behind those capabilities.
This is very different from the ATM example because again, each service is defining its own capabilities (functionality). With these capabilities is data ownership. Data isn’t owned by multiple bounded contexts. Building services with high functional cohesion is key in defining service boundaries.
Loosely Coupled
Coupling can be thought of in two ways. Afferent and Efferent Coupling.
If you’re thinking about a module/class/project:
Afferent Coupling (Ca) is what other modules depend on it.
Efferent Coupling (Ce) is what other modules does it depend on.
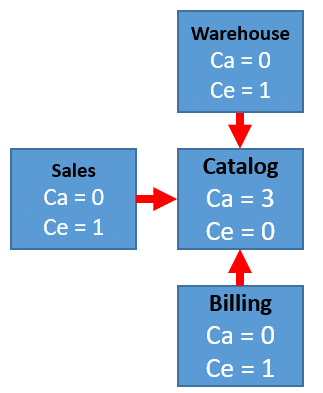
In this example, the Catalog module has an Afferent Coupling (Ca) of 3 because Warehouse, Sales, and Billing depend on it. The Catalog module has an Efferent Couling (Ce) of 0 because it depends on no other modules. Warehouse, Sales, and Billing all have an Afferent Coupling of 0 because no other module depends on them and an Efferent Coupling of 1 because they all depend on the Catalog.
If your modules are communicating in-process (monolith) over the network via an HTTP, they are still tightly coupled. Again, communicating via a REST HTTP API does not make your services less coupled or loosely coupled. This simply makes your system a distributed monolith.
What is loose coupling?
In computing and systems design a loosely coupled system is one in which each of its components has, or makes use of, little or no knowledge of the definitions of other separate components. Subareas include the coupling of classes, interfaces, data, and services. Loose coupling is the opposite of tight coupling.
https://en.wikipedia.org/wiki/Loose_coupling
If you think back to Adrian’s comment about a bounded context, about knowing too much, this is what he’s referring to. A way to achieve loose coupling is through a Message or Event Driven Architecture.
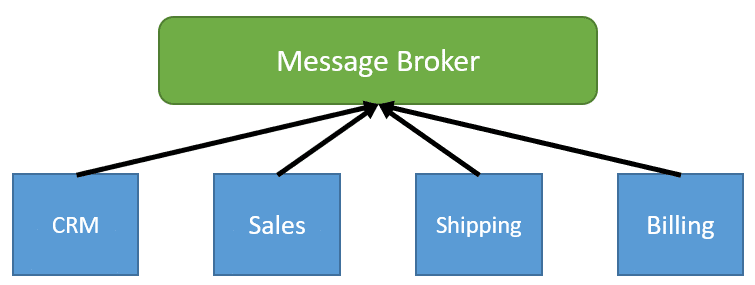
Instead of our services communicating directly with other services, we are sending and publishing events to a message broker. Each module consumes Events and reacts to them. The publisher of the events is totally unaware of who the consumers are or if there are any consumers at all.
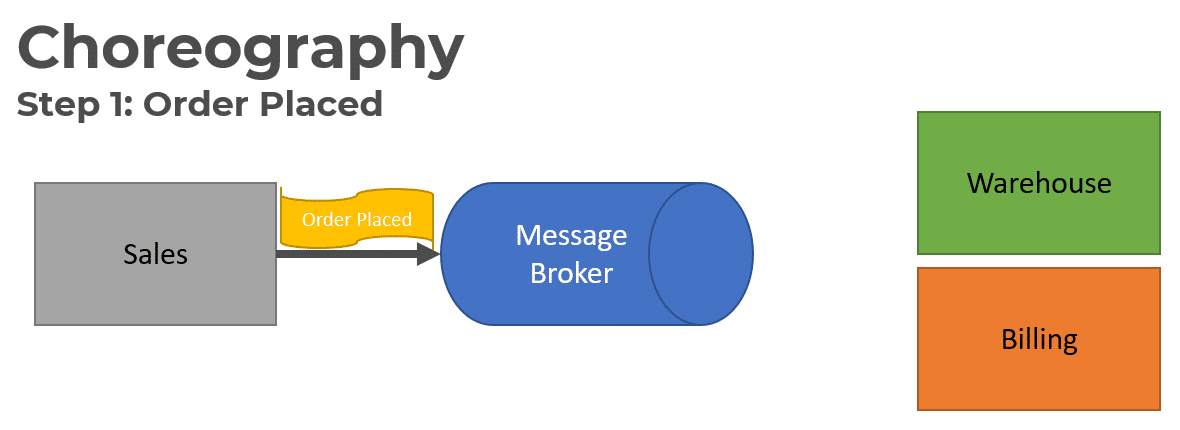
As an example in a long-running process of an e-commerce site of an order being placed, Event Choreography is used.
The first step is when an order is placed in the Sales service, an Order Placed Event is published to the message broker.
The Billing Service will consume that message and create an Invoice or Charge the customer.
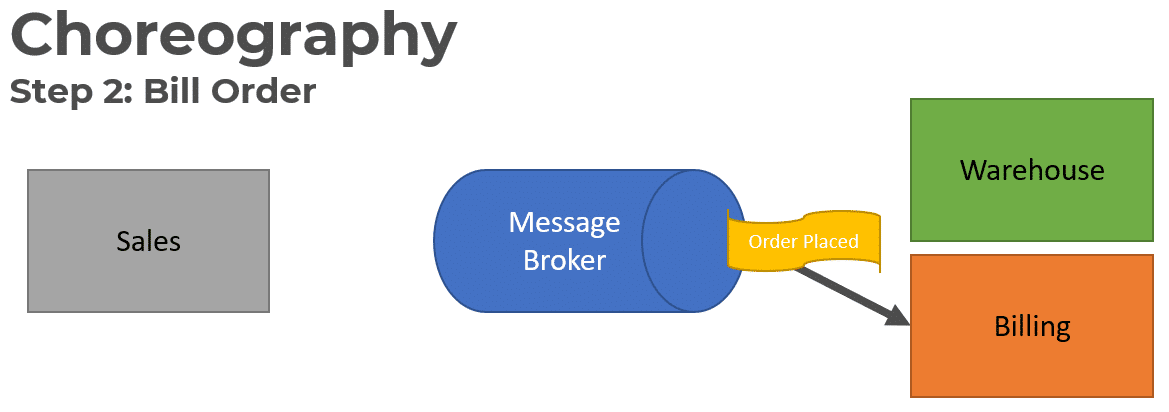
Once the Invoice or Customer has been charged the Billing service will publish an Order Billed event.
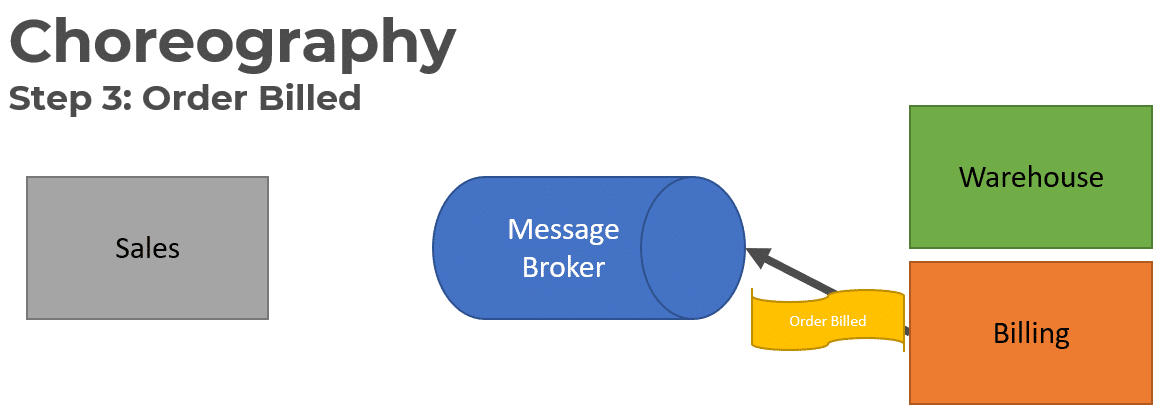
The Warehouse service will consume the Order Billed event in order to allocate product in the Warehouse.
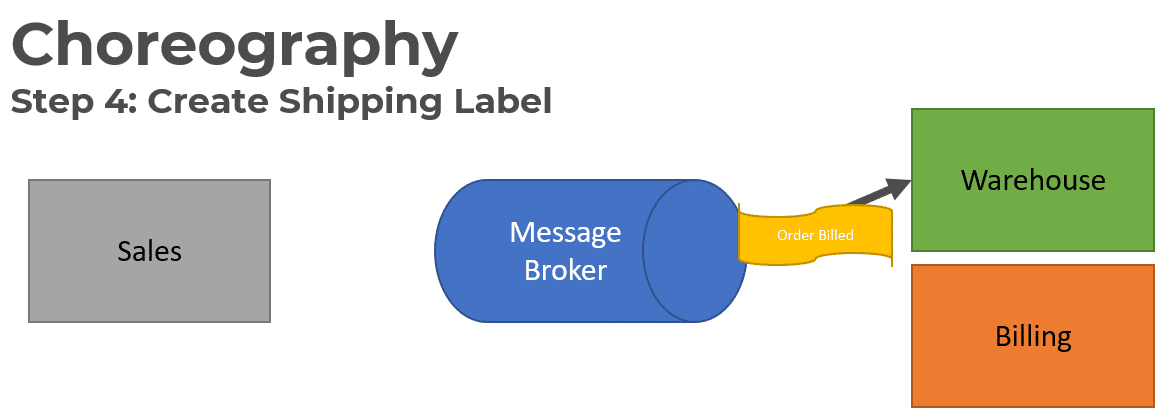
Once the product has been allocated and a shipping label has been created, it publishes a Shipping Label Created Event.
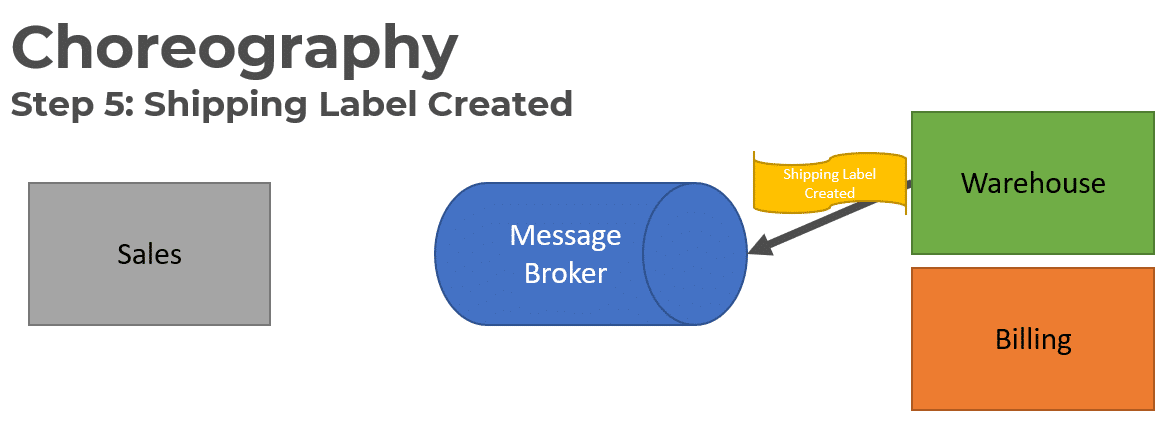
The Sales service consumes the Shipping Label Created event to update its Order Status.
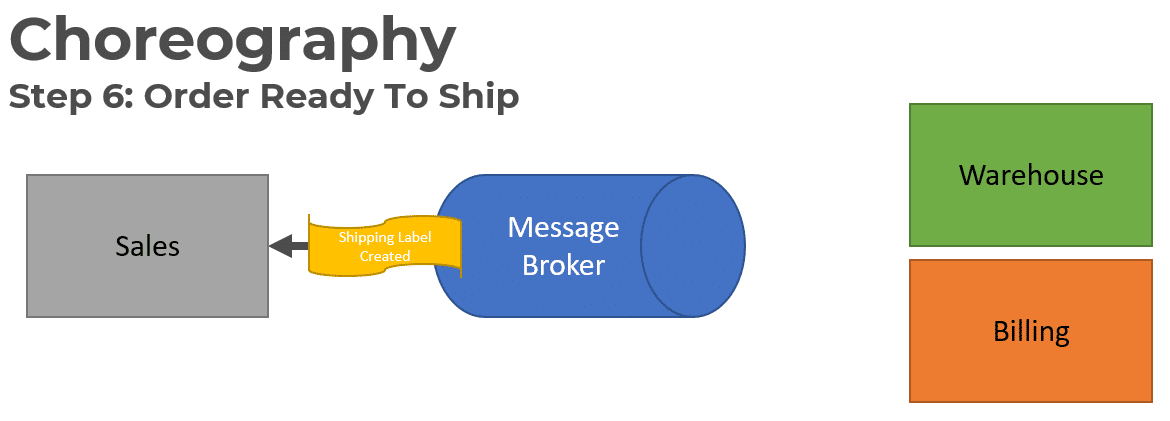
All of this workflow was done using Event Choregraphy. No service knew about the other services consuming the messages it was publishing. They are loosely coupled.
This means that Event Driven Architecture is a characteristic of a Microservices architecture.
For more on how this works for long-running business processes that span services can be managed check out my post on Event Choreography or Orchestration.
Does CAP Theorem apply to Microservices?
No. Absolutely not. Not when talking about Microservices as a part of a larger system.
Yes if you’re talking about the context of individual service. CAP can apply to individual service and if it chooses consistency or availability.
Services are about defining a set of business capabilities. Services do not share ownership over data. Services are loosely coupled through a Message and/or Event Driven Architecture.
There is no concern for consistency because there’s no data that needs to be consistent between services.
There is no concern for availability because each service is autonomous.
There is no concern for partition tolerance because each service is autonomous and loosely coupled.
Microservices are about the decomposition of a large system.