Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
An essential aspect of Event-Driven Architecture is understanding how your system is performing (throughput). Everything is running smooth, and services are publishing and consuming events, and then out of nowhere, one service starts failing or has a significant decrease in throughput, which then causes havoc to your system. Let me explain some of those reasons and why having metrics and alarms will allow you to proactively make changes to keep everything running smoothly.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Consumer Lag / Queue Length
If you’re using a typical queue-based broker, the queue length is the number of pending messages in your queue that need to be processed. The point of a queue is to have some length to it; however, where things go wrong when your producing more messages than you can consume.

In the example above, a single consumer handles messages from a queue. It can only process one message at a time. It must complete the processing of one message before it can consume the next. If you produce messages faster than you consume, you’ll backlog the queue.

There are peaks and valleys to processing messages. You may be producing more messages in bursts, which is what queues are great for. However, over a longer duration, if you continue on average produce more messages than you can consume, you’ll never be able to catch up and backlog the queue.
Scale-Out
To increase throughput and reduce consumer lag, one option is to scale out using the competing consumers’ pattern. This means adding more instances of your consumer so you can process messages concurrently.
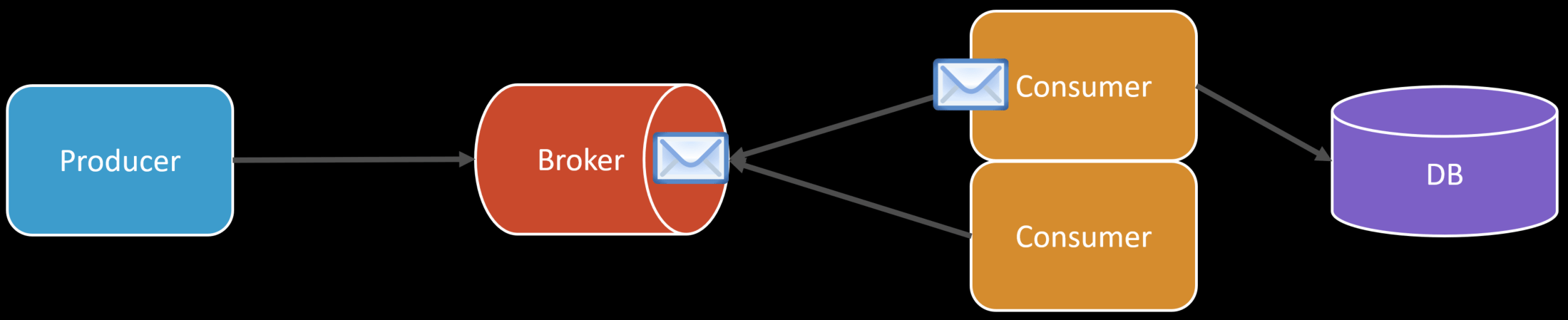
In the example above, there is a consumer that is free to process the next message in the queue, even though the other consumer is processing a message.
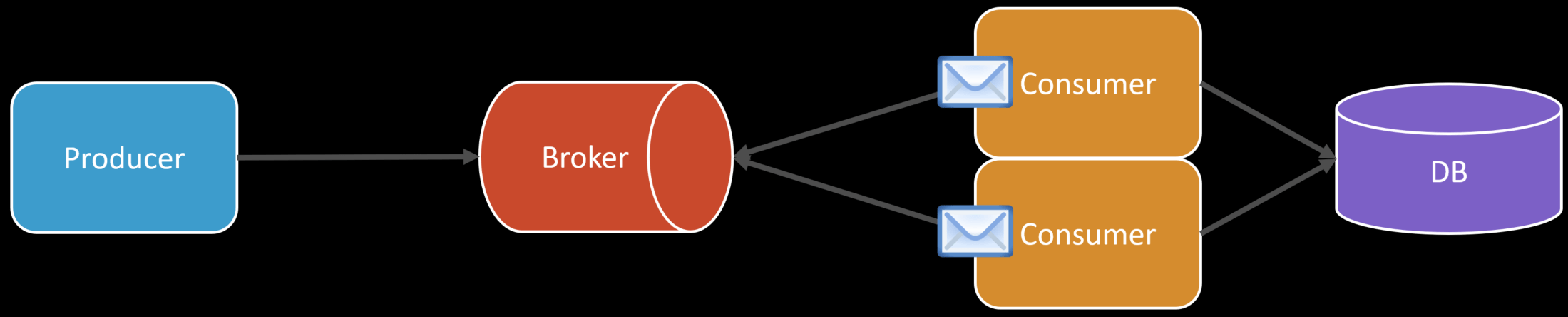
This means with two consumer instances, we can process two messages concurrently and doubling our processing.
However, one thing to notice here is since the queue was acting as a bottleneck, which is the point, we need to maintain a level of throughput so we don’t end up never being able to catch up. However, when we add more instances of our consumers, we could affect other downstream services or infrastructure. In this case, it’s our database.
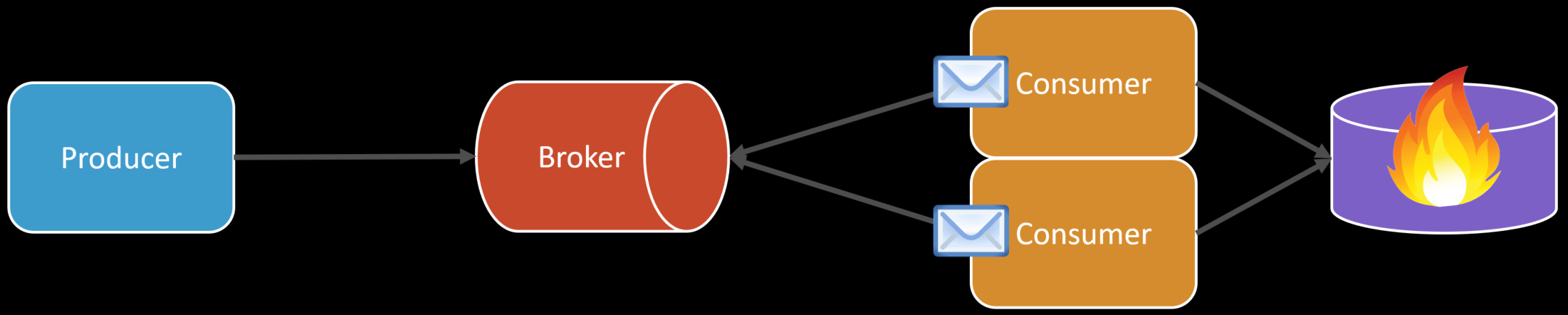
This means we are also going to increase the load on our database could have a negative impact on it. Be aware of moving the bottleneck and its implications on the rest of your system.
Processing Time
Another option to increase throughput is increasing the processing time. Meaning when we process a message, if it currently takes 200ms and we make optimizations that result in the total processing time of a message being 100ms, we just double our throughput.
The exact opposite can happen, however, which can cause our processing time to increase, resulting in our queue length growing. One common reason for this is external systems.
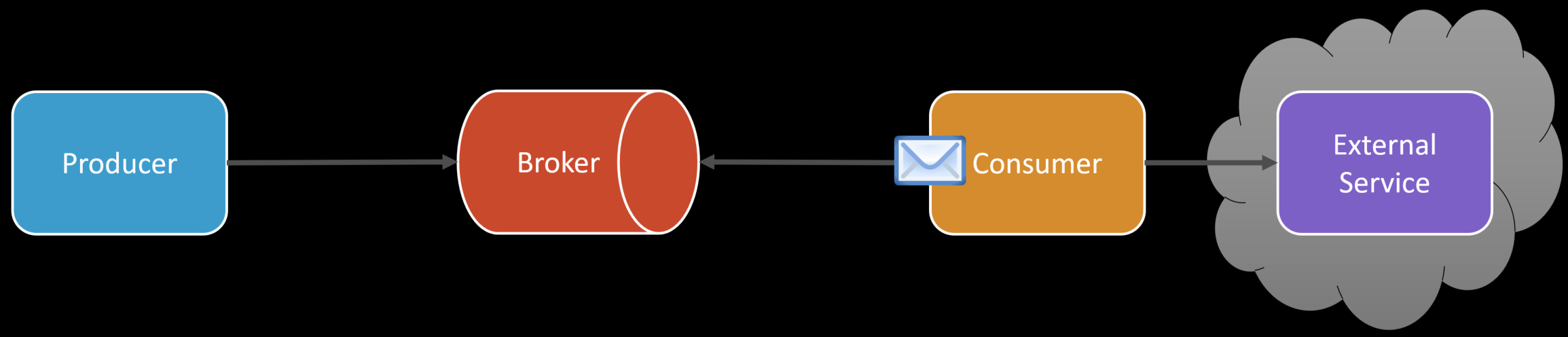
Let’s say we need to make an HTTP call to an external service. On average, it takes 100ms to complete the request. If all of a sudden there are availability issues and our call fails? How are we handling that? What if the external service is timing out, and we don’t have any timeouts built in place, and it takes 60 seconds?
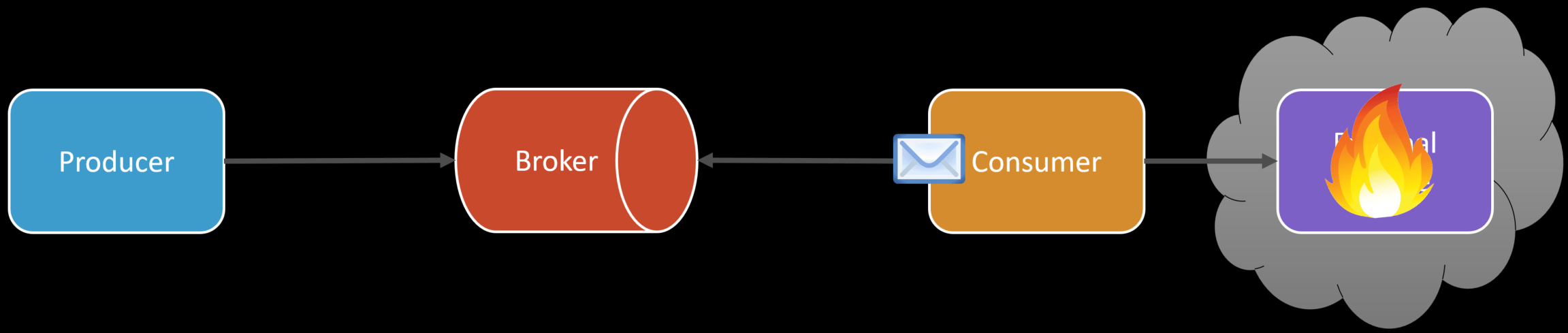
This would be a total disaster and cause our queue length to increase alarmingly if our production rate was say, 5 per second.
Partitions and Ordering
One of the reasons I find people use Kafka is because of partitions it’s designed to have a single consumer within a group be associated with a partition. This means that can process messages from a partition in order. This also means you cannot apply the competing consumers’ pattern by partition. In other words, if you have 2 partitions and 3 consumers, only 2 of them will actually be doing any work.

In the example above, my topic has two partitions (P1 and P2). I’ve created two consumers within a consumer group (P1 Consumer and P2 Consumer).
When a message is placed on the P1, only the P1 Consumer will process it. As you might guess, what happens when any of the above scenarios happen? We’re going to experience consumer lag because more messages are be published to P1 than can be consumed.
If you’re using Kafka and partitions specifically because of ordered processing, this means if you have a poison message that you can’t consume, you’ll experience consumer lag.

At this point, you can other discard the message if possible and continue, or you’ll have to block and wait till you can resolve the issue with the poison message.
Monitoring
Monitoring is critical to message-driven systems using queue-based brokers or event-streaming platforms. Having metrics around your throughput and alarming when you start experiencing any type of consumer lag or queue length.
Metrics around queue length, processing times, throughput, and critical time are all metrics that should be monitored, and appropriate alarms when thresholds are reached. Be proactive and understand how you plan on increasing throughput.
Join!
Developer-level members of my YouTube channel or Patreon get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.