Sponsor: Using RabbitMQ or Azure Service Bus in your .NET systems? Well, you could just use their SDKs and roll your own serialization, routing, outbox, retries, and telemetry. I mean, seriously, how hard could it be?
There’s been a noticeable pushback against microservices lately, and we’re seeing a strong swing back toward monoliths. But I have to ask, if you can’t build a solid microservices system, what makes you think you can build a good monolith?
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Understanding the Basics: Network Calls
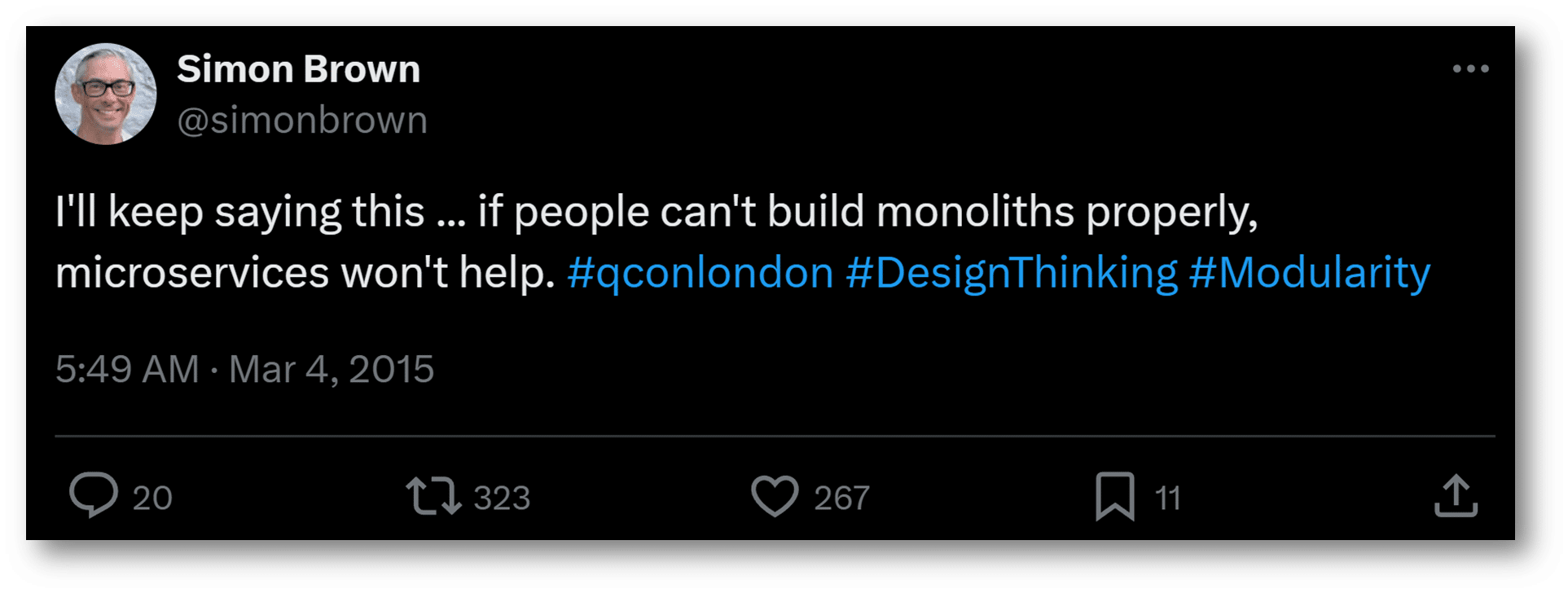
Nearly a decade ago, Simon Brown echoed a similar sentiment, just in reverse of today, and I believe the reasons remain unchanged.
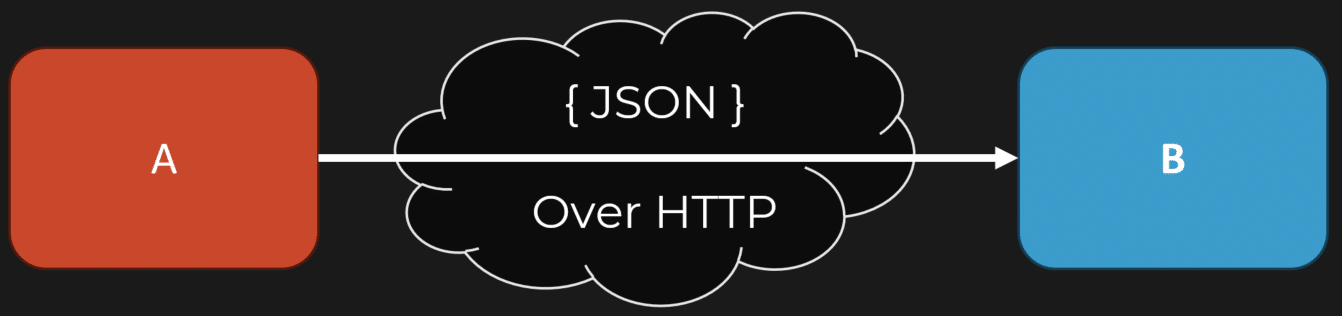
Let’s dive into the fundamentals first. Imagine we have two components, A and B. A calls B. In a monolith, this is a straightforward in-process, in-memory function call.

But when we switch to microservices, this same call becomes an RPC (Remote Procedure Call). Instead of a simple function call, we’re now making requests over the network, often using HTTP or gRPC. So, while it seems like we’re doing the same thing, we’ve introduced a network call, which can complicate matters significantly.
Network Calls
When microservices became popular, many thought, “It’s just a network call; how hard can it be?” But this mindset overlooks the complexities that arise from network communication. The root of many pain points people experience with microservices stems from these network calls. Let’s break down a few of the challenges:
- Latency: Network calls introduce overhead. For example, if service A calls service B, which then calls service C, and so on, you might think you’re just waiting on service B. However, the total time could be much higher due to the cumulative latencies of each downstream service.
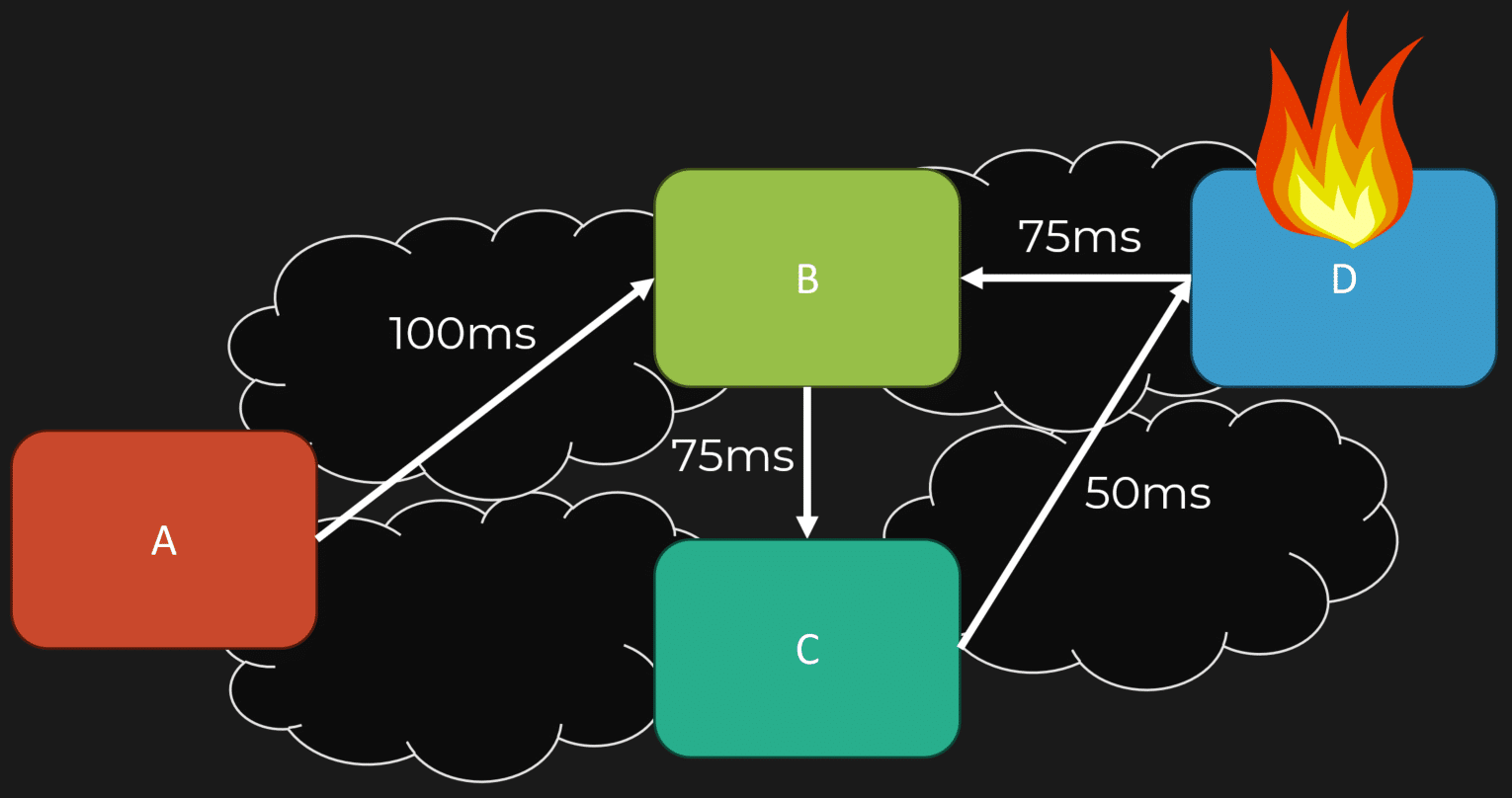
- Visibility: From the perspective of service A, if requests to service B are taking longer, it’s easy to blame service B without realizing the issue might lie deeper down the chain.
- Coordination: Often, microservices need to be deployed together due to breaking changes across services. This coordination can lead to a “distributed monolith,” where the overhead of network calls creates many of the same issues we tried to escape.
Monoliths: The Alternative?
So, is a monolith the better option? While a monolith can mitigate some of the pain points associated with microservices — like latency and visibility — it doesn’t automatically solve the fundamental issues of coupling. If you can’t build effective microservices, what makes you think you can build a monolith? The high degree of coupling often exists in both architectures, making it hard to understand the implications of changes.
The crux of the issue lies in how we focus on entities and data. There’s a prevalent belief that we should create services based on data tables. But this leads to unnecessary coupling.
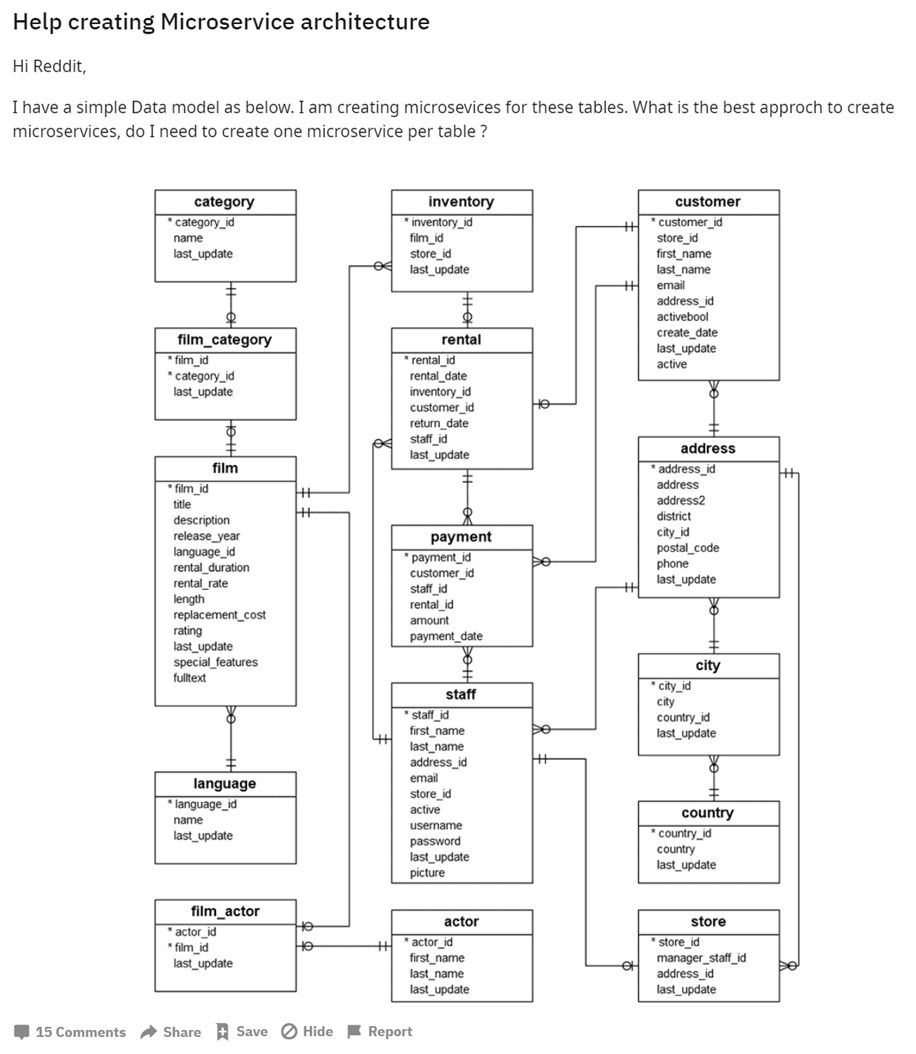
I often reference a Reddit post that illustrates this point: if you’re building microservices based on tables, you’re likely making a mistake. The same applies to monoliths; don’t create modules based on tables.
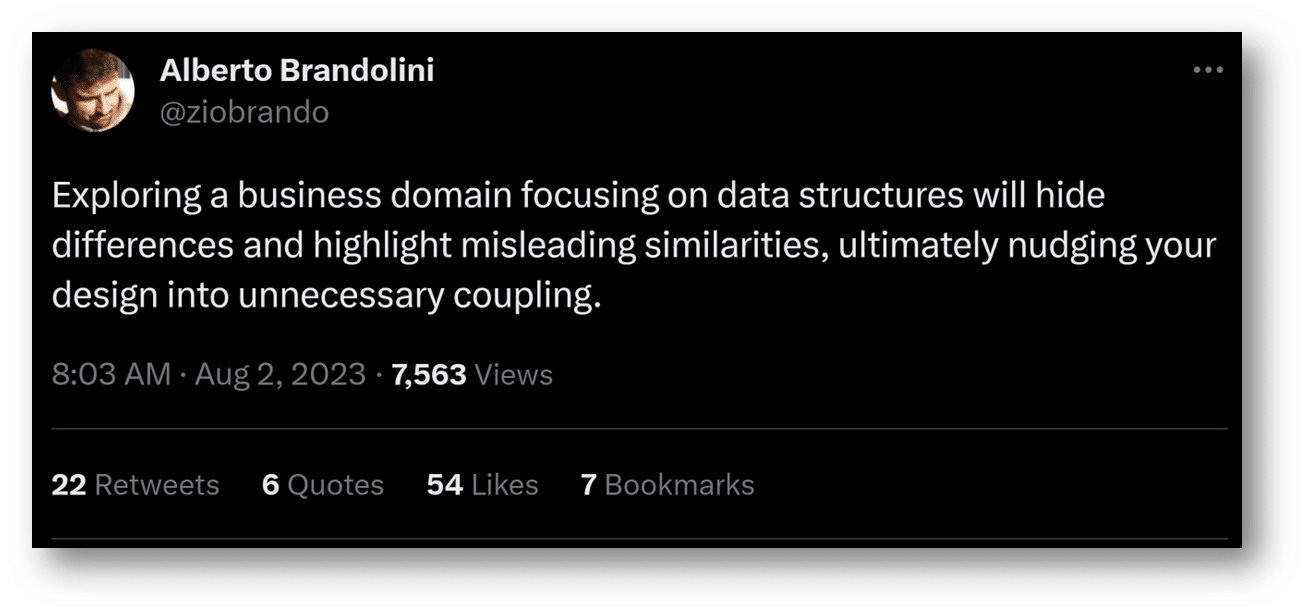
Instead of fixating on data, we should concentrate on business capabilities. A business capability defines an organization’s ability to perform a unique business activity. So, when you’re building modules or services, think about what business activity they expose and what they do, rather than what data they manage.
Finding Solutions
So, how do we manage coupling effectively? It’s all about defining boundaries. If you’re in a microservices environment and you’ve achieved independent deployability while managing coupling, would your perspective shift? If you can manage coupling well in a microservices setting, those pain points can diminish.
Let’s consider a practical example. You have an HR department that handles payroll and an IT department that manages various accounts. The banking information for payroll likely resides in HR, not IT. If HR had to reach out to IT every time payroll needed to run, that would create unnecessary coupling. Instead, the concept of an employee can exist in multiple places, with each department managing the data relevant to their functions.
The key takeaway is to focus on business capabilities rather than data structures. Whether you’re building a monolith or microservices, it’s about how manage coupling effectively. If you can’t build a robust microservices environment focused on capabilities, it’s unlikely that a monolithic architecture will be any better. You’ll just be trading one set of pain points for another.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.